Clustering techniques are unsupervised algorithms that try to group unlabelled data into “clusters”, using the (typically spatial) structure of the data itself. It has many applications.
The easiest way to demonstrate how clustering works is to simply generate some data and show them in action. We’ll start off by importing the libraries we’ll be using today.
import math, matplotlib.pyplot as plt, operator, torchfrom functools import partial
/Users/anubhavmaity/mambaforge/envs/fastai/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
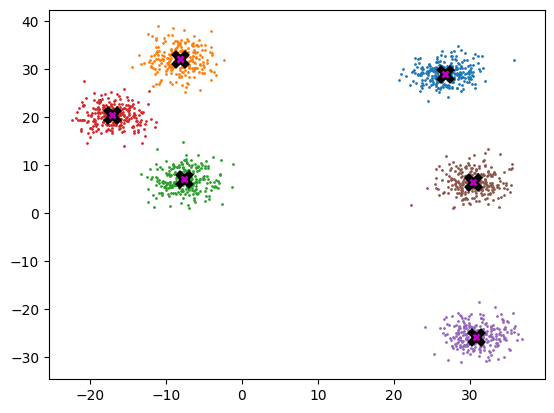
To generate our data, we are going back to pick 6 random points, which we will call centroids, and for each point we are going to generate 250 random points about it.
Most people that have come across clustering algorithms have learnt about k-means. Mean shift clustering is a newer and less well-known approach, but it has some important advantages: - It doesn’t require selecting the number of clusters in advance, but instead just requires a bandwidth to be specified, which can be easily chosen automatically. - It can handle clusters of any shape, whereas k-means (without using special extensions) requires that clusters be roughly ball shaped
The algorithm is as follows: - For each data point x in the sample X, find the distance between that point x and every other point in X - Create weights for each point in X by using the Gaussian kernel of that point’s distance to x - This weighting approach penalizes points further away from x - The rate at which the weights fall to zero is determined by the bandwidth, which is the standard deviation of the Gaussian - Update x as the weighted all other points in X, weighted based on the previous step
This will iteratively push points that are close together even closer until they are next to each other
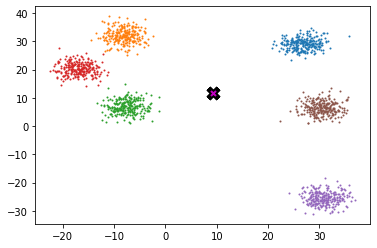
midp = data.mean(0)midp
tensor([ 9.222, 11.604])
plot_data([midp]*6, data, n_samples)
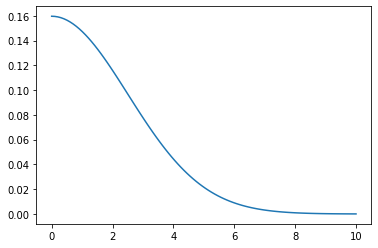
So here is the definition of the gaussian kernel, which you may remember from high school..
def meanshift(data, bs=500): n =len(data) X = data.clone()for it inrange(5):for i inrange(0, n, bs): s =slice(i, min(i+bs, n)) weight = gaussian(dist_b(X, X[s]), 2.5) div = weight.sum(1, keepdim=True) X[s] = weight@X/divreturn X
Although each iteration still has to launch a new cuda kernel, there are now fewer iterations, and the acceleration from updating a batch of points more than makes up for it.
data = data.cuda()
X = meanshift(data).cpu()
2.25 ms ± 36 µs per loop (mean ± std. dev. of 7 runs, 5 loops each)
plot_data(centroids +2, X, n_samples)
45 ms ± 654 µs per loop (mean ± std. dev. of 7 runs, 5 loops each)