This notebook is introduction to data in the competition Wattbot 2025
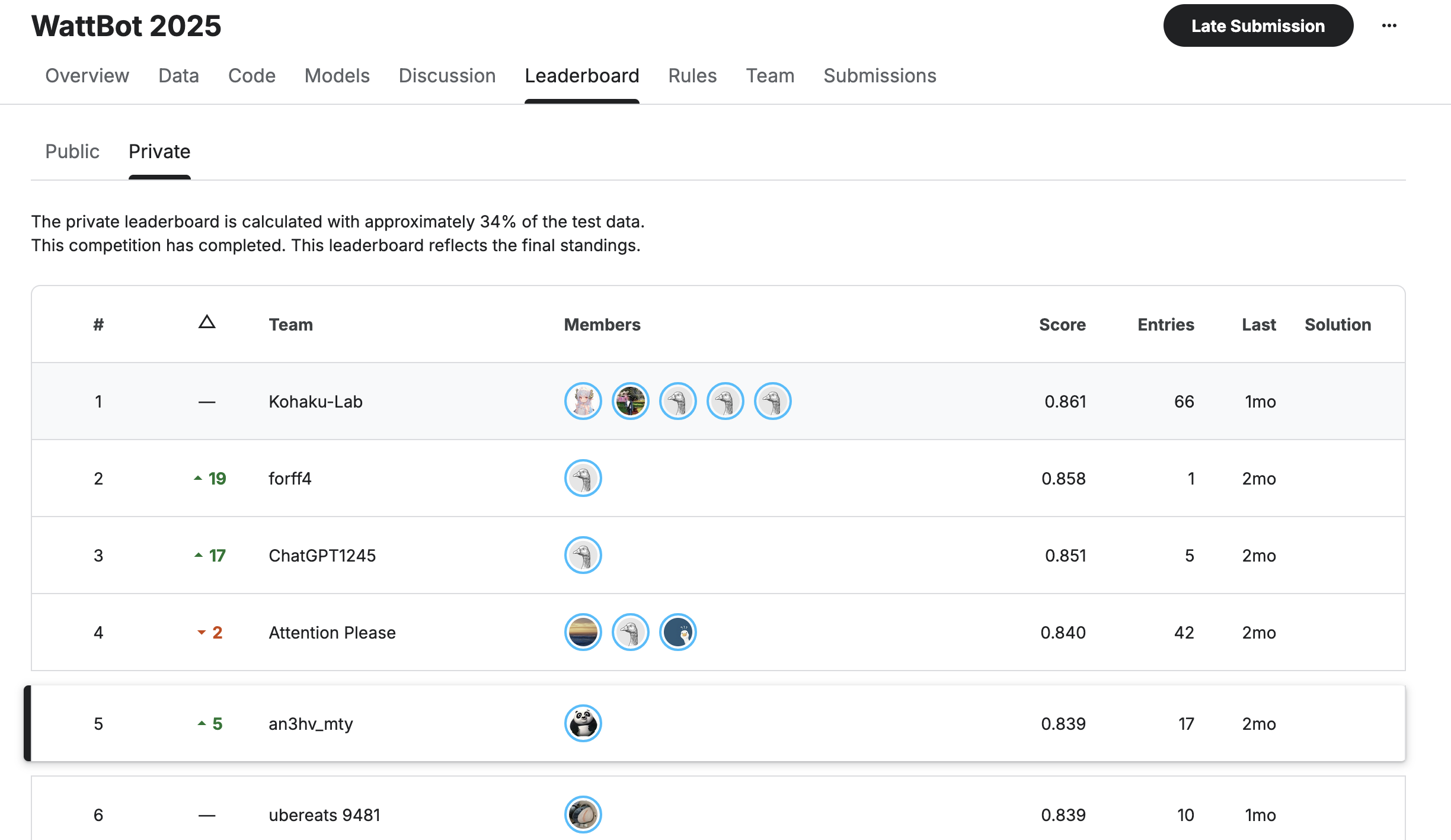
I participitated in this competition few months back and was ranked 5th in the Private Leaderboard and 10th in the Public Leaderboard. There were 182 entrants
Leaderboard Ranking
Looking at data
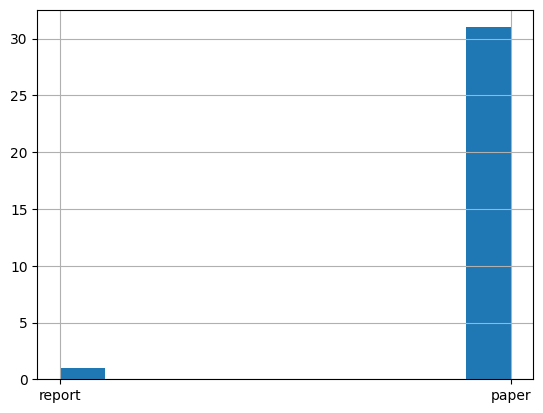
There are 3 files shared in the competition - metadata.csv - test_Q.csv - train_QA.csv
I have created a folder data and have downloaded all the 3 files into it
metadata().head()
id
type
title
year
citation
url
0
amazon2023
report
2023 Amazon Sustainability Report
2023
Amazon Staff. (2023). Amazon Sustainability Re...
https://sustainability.aboutamazon.com/2023-am...
1
chen2024
paper
Efficient Heterogeneous Large Language Model D...
2024
Shaoyuan Chen, Wencong Xiao, Yutong Lin, Mingx...
https://arxiv.org/pdf/2405.01814
2
chung2025
paper
The ML.ENERGY Benchmark: Toward Automated Infe...
2025
Jae-Won Chung, Jiachen Liu, Jeff J. Ma, Ruofan...
https://arxiv.org/pdf/2505.06371
3
cottier2024
paper
The Rising Costs of Training Frontier AI Models
2024
Ben Cottier, Robi Rahman, Loredana Fattorini, ...
https://arxiv.org/pdf/2405.21015
4
dodge2022
paper
Measuring the Carbon Intensity of AI in Cloud ...
2022
Jesse Dodge, Taylor Prewitt, Remi Tachet Des C...
https://arxiv.org/pdf/2206.05229
len(metadata())
32
There are 32 files
train().head()
id
question
answer
answer_value
answer_unit
ref_id
ref_url
supporting_materials
explanation
0
q003
What is the name of the benchmark suite presen...
The ML.ENERGY Benchmark
ML.ENERGY Benchmark
is_blank
['chung2025']
['https://arxiv.org/pdf/2505.06371']
We present the ML.ENERGY Benchmark, a benchmar...
Quote
1
q009
What were the net CO2e emissions from training...
4.3 tCO2e
4.3
tCO2e
['patterson2021']
['https://arxiv.org/pdf/2104.10350']
"Training GShard-600B used 24 MWh and produced...
Quote
2
q054
What is the model size in gigabytes (GB) for t...
64.7 GB
64.7
GB
['chen2024']
['https://arxiv.org/pdf/2405.01814']
Table 3: Large language models used for evalua...
Table 3
3
q062
What was the total electricity consumption of ...
Unable to answer with confidence based on the ...
is_blank
MWh
is_blank
is_blank
is_blank
is_blank
4
q075
True or False: Hyperscale data centers in 2020...
TRUE
1
is_blank
['wu2021b','patterson2021']
['https://arxiv.org/abs/2108.06738','https://a...
Wu 2021, body text near Fig. 1: "…between trad...
The >40% statement is explicit in Wu. Patterso...
get_train_data()
namespace(id='q166',
question='Which of the following five large NLP DNNs has the highest energy consumption: Meena, T5, GPT-3, GShard-600B, or Switch Transformer?',
answer='GPT-3',
answer_value='GPT-3',
answer_unit='is_blank',
ref_id="['patterson2021']",
ref_url="['https://arxiv.org/pdf/2104.10350']",
supporting_materials='Figure 3',
explanation='Figure')
get_train_data(0)
namespace(id='q003',
question='What is the name of the benchmark suite presented in a recent paper for measuring inference energy consumption?',
answer='The ML.ENERGY Benchmark',
answer_value='ML.ENERGY Benchmark',
answer_unit='is_blank',
ref_id="['chung2025']",
ref_url="['https://arxiv.org/pdf/2505.06371']",
supporting_materials='We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments...',
explanation='Quote')
get_value(train().iloc[0])
namespace(id='q003',
question='What is the name of the benchmark suite presented in a recent paper for measuring inference energy consumption?',
answer='The ML.ENERGY Benchmark',
answer_value='ML.ENERGY Benchmark',
answer_unit='is_blank',
ref_id="['chung2025']",
ref_url="['https://arxiv.org/pdf/2505.06371']",
supporting_materials='We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments...',
explanation='Quote')